

Technologie is niet neutraal
“AI is op dit moment een hetero westerse witte man, en dat is een groot probleem.” Dit is deel 2 van onze her/ai Ethics of AI-serie over de bias van AI.


Stel je voor: je bent masterstudent aan de VU Amsterdam, het is midden in de coronacrisis en je moet thuis tentamen maken. Je downloadt braaf Proctorio, een gezichtsherkenningssoftware die controleert of je niet spiekt. Je start het programma op, een kwartier vóór het tentamen, zodat je zonder stress aan je belangrijke toets kunt beginnen.
Maar de software blijft errormeldingen geven. 'Gezicht niet herkenbaar.' 'Te donker.' De klok tikt. Je kunt je tentamen niet starten omdat de software je gewoon niet herkent. De oplossing van de VU? Maak je tentamen maar met een grote ringlamp gericht op je gezicht - je weet wel, zo'n ding waar influencers mee rondlopen.
Dit overkwam Robin Pocornie drie jaar geleden. De software herkende haar donkere huidskleur simpelweg niet. En zij is helaas geen uitzondering: er zijn duizenden voorbeelden van technologie die mensen benadeelt op basis van huidskleur, geslacht, afkomst of andere kenmerken.
“AI draagt op dit moment het gezicht van een hetero westerse witte man, en dat zorgt voor een gevaarlijk probleem.”
Want waar we graag denken dat technologie een gelijkmaker is, blijkt in de praktijk het tegenovergestelde waar. Het versterkt juist de ongelijkheden die al bestonden.
Want hier is de realiteit: technologie is niet neutraal. AI ook niet.
Om te begrijpen waarom, moeten we eerst het verschil snappen tussen algoritmes en AI.
Algoritmes = instructies waarbij de regels door mensen zijn bedacht. Denk aan de toeslagenaffaire en de DUO-fraudeschandalen. Iemand had de regels opgesteld: tweede paspoort = risico. Student woont bij ouders + bepaald diplomaniveau = fraudeverdachte.
AI = de machine bepaalt zelf de regels op basis van heel veel data. Maar hier zit het probleem: die data is allesbehalve neutraal.
Vier redenen waarom de data allesbehalve neutaal is
1. Data is altijd historisch
Terwijl wij als vrouwen strijden voor een eerlijke toekomst, wordt technologie getraind op een verleden waar we juist van af willen. Een LinkedIn-post van Eline de Wit en Lize Hong laat dit pijnlijk goed zien. Eline vroeg AI om salarisadvies: als ‘Chad’ kreeg ze €120.000 meer voorgesteld dan als ‘Ellie’. Lize liet ChatGPT haar brandsprint prijzen: €20-30K als ‘Lize en Andrada’, maar €30-40K als ‘Peter en Eric’. Exact hetzelfde werk, maar een prijsverschil van 30%.
En dit is niet één model. ChatGPT, Claude, Gemini – ze doen het allemaal. Want AI leert van miljoenen teksten, fotos en filmpjes waarin deze bias al lang bestaat. AI maakt het alleen sneller, schaalbaar en onzichtbaar.
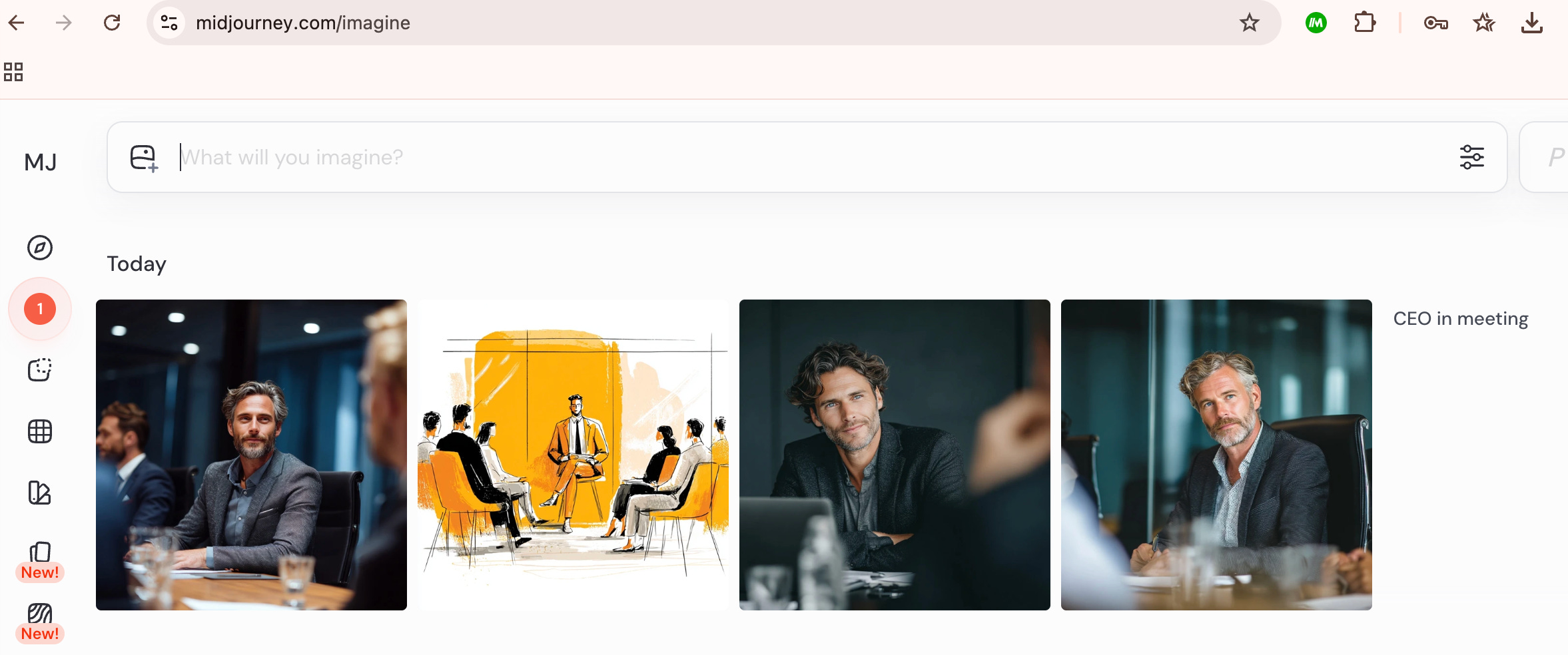
Een voorbeeld uit het beeldmodel Midjourney: als wij ‘CEO in meeting’ invoeren als prompt, krijgen we zonder uitzondering afbeeldingen terug van witte mannen van middelbare leeftijd.
2. Data is niet compleet
Waar geen data over bestaat, kan het model niet op trainen. AI-datasets komen overwegend uit de VS. De large language modellen zijn daardoor een weerspiegeling van de westerse cultuur, en vooral van die 15% van de wereldbevolking die Engels spreekt.
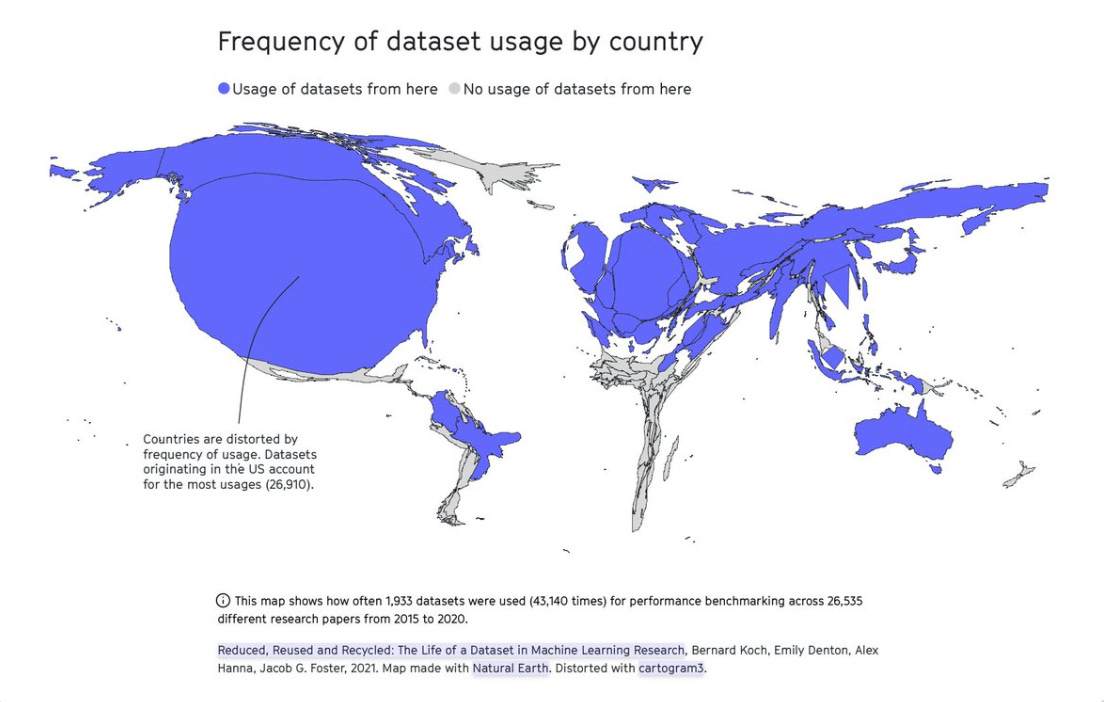
Een test met Indiase en Amerikaanse schrijvers die AI-schrijfhulp gebruikten, laat dit glashelder zien: de Indiase schrijvers moesten de suggesties constant corrigeren, wat resulteerde in veel minder productiviteitswinst. Het LLM snapt hun manier van uitdrukken gewoon minder goed.
En dan de medische wereld. AI voor leverziektedetectie mist de ziekte bij vrouwen twee keer zo vaak als bij mannen (UCL, 2022). Dermatologiedatasets bevatten slechts 4-18% afbeeldingen van donkere huid. MIT-onderzoek uit 2024 toont aan: AI-modellen voor diagnose presteren slechter bij vrouwen en mensen van kleur.
3. Data heeft stereotype vooroordelen
AI-systemen leren niet alleen wat er is, maar ook wat mensen denken dat er is. En dat is het gevaarlijke: onrealistische stereotypen worden in de systemen gegrift alsof ze feiten zijn.
Neem Ilia Savelev. Hij vermoedde fraude op zijn bankrekening en belde de bank. Klinkt normaal, toch? Maar het spraakherkenningssysteem van de bank concludeerde dat zijn stem niet ‘mannelijk’ genoeg was om overeen te komen met zijn geregistreerde gegevens. Hij kon letterlijk niet geholpen worden omdat zijn stem niet paste in het hokje dat AI voor hem had bedacht. De AI had een stereotiep beeld van hoe een ‘mannenstem’ hoort te klinken, en Ilia voldeed daar niet aan. Voor de LHBTQIA+-gemeenschap is dit helaas vaker de realiteit.
En hier wordt het bijna komisch, als het niet zo triest was: de spraakherkenning van Google werkt 13 procent beter voor mannen dan voor vrouwen. Maar als je je AI-assistent aanzet? ‘Hello Alexa.’ ‘Hi Siri.’ Vrouwenstemmen, altijd. AI verstaat vrouwen slechter, maar laat ze wel het digitale assistentwerk doen.
4. Data heeft ogenschijnlijk onschuldige variabelen die mensen benadelen
Dit is misschien wel het engste: AI vindt verbanden die wij als mens niet eens door hebben. Neem kredietbeoordeling op basis van postcode. Lijkt onschuldig, toch? Maar postcode correleert sterk met etniciteit in veel landen. Het resultaat: discriminatie zonder dat er ooit expliciet naar huidskleur of afkomst is gevraagd.
Of neem de hiring-AI van Amazon. Die beoordeelde sollicitanten lager wanneer het woord ‘women’ in hun cv stond, bijvoorbeeld bij ‘women’s chess club captain’. De AI had geleerd dat mannen historisch gezien vaker werden aangenomen, dus dat moest wel het juiste patroon zijn. Amazon heeft het systeem uiteindelijk moeten schrappen.
En nu? Wat wordt hier aan gedaan?
1. Decentralisatie van modellen
Klein maar krachtig voorbeeld: in 2018 organiseerde een non-profitradiostation in Nieuw-Zeeland een wedstrijd. Maori-sprekers in heel Nieuw-Zeeland maakten in tien dagen ruim 300 uur aan opnames in hun moedertaal. Genoeg data om een AI-model specifiek voor Te Reo Maori te ontwikkelen.
Dit wordt steeds meer mogelijk door open-sourcemodellen die klein en goedkoop zijn. Zo kunnen kleinere groepen, modellen maken die zijn afgestemd op hun werkelijkheid, hun data, hun taal.
2. Eerlijke adoptie
Dit is precies waarom wij her/ai zijn gestart. Om vrouwen (en minderheden) te ondersteunen bij het werken met AI. Want hoe minder diverse mensen AI gebruiken en vormgeven, hoe meer de systemen zich in dezelfde eenzijdige richting ontwikkelen.
Noors onderzoek toont aan: wanneer AI-gebruik bij vrouwen expliciet wordt aangemoedigd, helpt het de genderkloof te verkleinen. Het gaat om toestemming en gestructureerde begeleiding
3. Synthetische data (met de nodige voorzichtigheid)
Synthetische data kan helpen om vaak vergeten groepen extra aandacht te geven tijdens de training. Maar pas op: het kan ook 'nep-diversiteit' creëren die vooral bedrijven helpt, zonder dat er werkelijk iets verandert.
Wat betekent dit voor jou, vandaag?
Je bent je nu bewust van de vooroordelen die in de modellen zitten. Neem dat mee wanneer je met ChatGPT of een ander LLM werkt.
Geef AI nooit het laatste woord.
Zorg altijd voor een mens in de besluitvorming.
En vooral: gebruik AI om jou te helpen, niet om controle over anderen uit te oefenen.
Dit artikel is voor iedereen gratis te lezen. Als je deze gratis content waardevol vindt, overweeg dan om betaald abonnee te worden (€7/maand voor extra wekelijkse nieuwsbrieven)
Je kunt ons ook eenmalig op een ☕️ trakteren! Dat doe je hier.
Wij maken her/ai naast ons werk, en elke bijdrage helpt ons de tijd vrij te maken om onze missie voort te zetten: vrouwen de tools geven om vol vertrouwen AI in te zetten. Dank je wel!