

Privacy: Waar liggen de risico’s en wat kan ik er aan doen?
Deel 1 van onze her/ai Ethics of AI-serie


We hebben het de afgelopen weken gehad over hoe je AI-modellen kiest, hoe je goed prompt, en hoe je je eigen assistenten bouwt. Allemaal praktisch, allemaal gericht op resultaat. En dat blijven wij ook doen.
Maar. Er is één ding waar we niet omheen kunnen: de ethische kant van AI. Want al die handige tools komen met vragen waar je niet onderuit komt. Hoewel ons platform zich richt op de praktische toepassing van AI, vinden we het noodzakelijk om een Ethics of AI-serie te schrijven. Zodat jullie geïnformeerd en bewust AI kunnen inzetten om productiever te zijn.
We beantwoorden 6 belangrijke vragen:
Privacy: Waar liggen de risico’s en wat kan ik er aan doen?
Klimaat: Hoeveel energie gebruikt AI eigenlijk?
Bias: Welke vooroordelen heeft AI allemaal?
Democratie: Hoe is AI een risico voor onze democratie?
Eigenaarschap: Hoe zit het nou met auteursrecht?
Creativiteit: Verleer ik denken en bedenken als AI het overneemt?
Vandaag aan de beurt: Wat gebeurt er eigenlijk met al die data die je in ChatGPT, Claude en Gemini stopt?
Laten we beginnen met wat privacy eigenlijk is en waar de risico’s liggen
Privacy is niet hetzelfde als geheimhouding. Privacy is niet “ik heb iets te verbergen”. Privacy is controle over je eigen informatie.
Zodra iemand informatie over jou heeft zonder dat jij dat wilde of wist, ontstaat er een machtsverschil. Dáár zit het risico. En helaas: bij AI-gebruik is dat risico reëel.
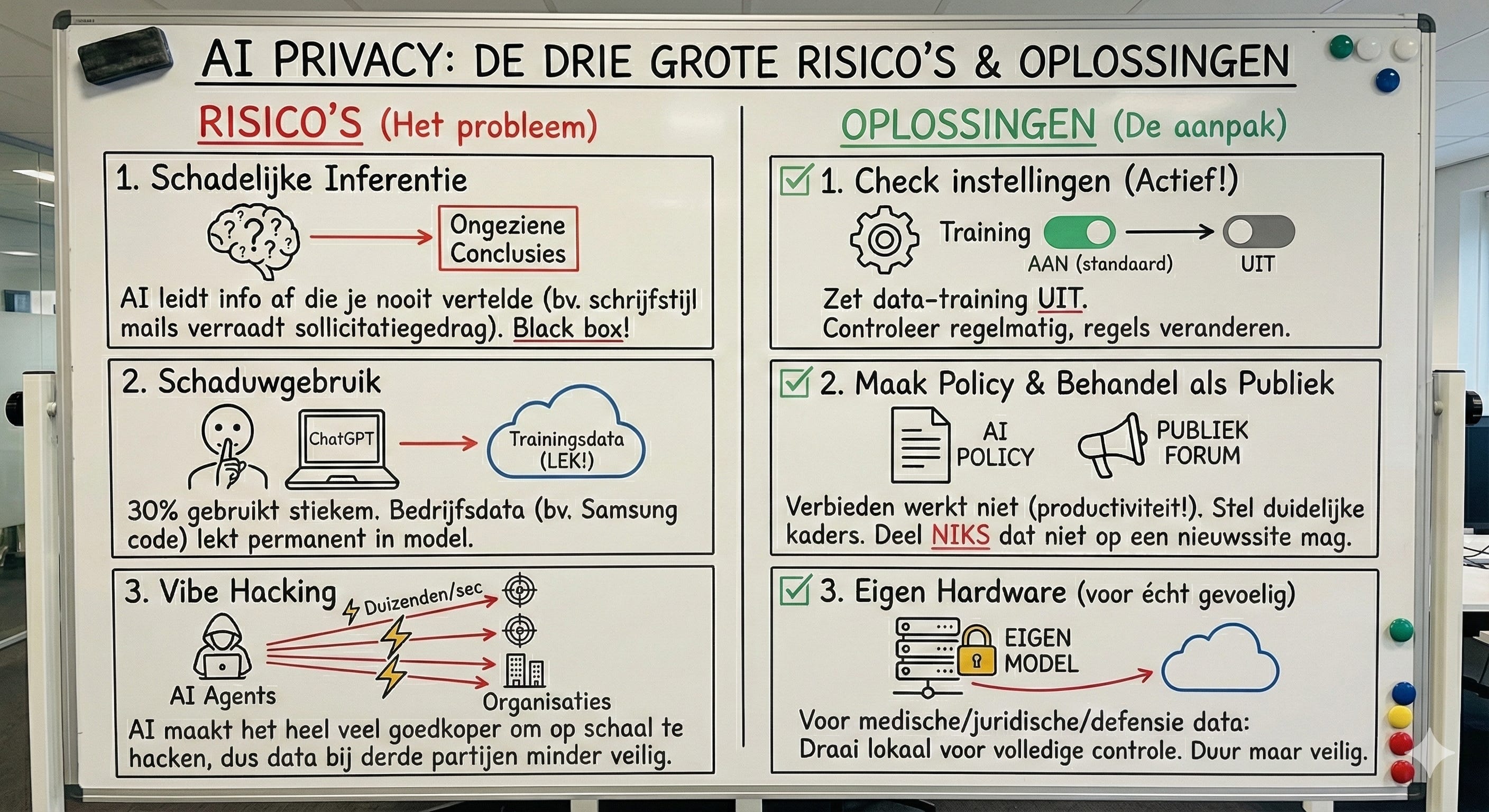
Risico 1 - AI leidt dingen af die je nooit verteld hebt
Dit risico kennen wij al langer: Netflix wist dat ik van biografische vrouwenfilms hield voordat ik het zelf doorhad. Redelijk onschuldig en daar heb ik toestemming voor gegeven want ik hou wel van een gepersonaliseerde selectie films.
Maar hoe zit dat met de nieuwe AI platforms?
Bij gratis of plus-accounts van AI-tools wordt je data gebruikt “om het model beter te maken”.
Een model trainen moet je zien als een cake bakken. Je stopt ingrediënten erin (data), het gaat de oven in (training draait weken- of maandenlang), en komt eruit als een afgewerkt product. Daarna is het klaar.
Hier wordt het gevaarlijk: het bakproces is een black box. Het model leert zichzelf patronen aan zonder dat wij precies begrijpen wat het leert of waarom. Dit heet unsupervised learning - het model zoekt zelf naar patronen, zonder dat iemand aangeeft welke patronen belangrijk zijn.
Een concreet voorbeeld: miljoenen mensen gebruiken ChatGPT om werkmails te schrijven. Het model leert dan patronen: welke woorden komen vaak voor in mails van mensen die kort daarna ontslag nemen? Welke zinnen gebruikt iemand die aan het solliciteren is? Die verbanden worden gebakken in het model, niet omdat OpenAI dat wilde, maar omdat het model zélf die patronen ontdekt.
Nu komt het punt: die kennis zit er permanent in. Dus als jij morgen je mails uploadt, kan het model daar mogelijk iets uit afleiden over jouw werksituatie. Niet omdat je het verteld hebt, maar omdat jouw taalgebruik overeenkomsten heeft met patronen die het geleerd heeft van anderen.
Waarom dit gevaarlijk is
Dit risico treft vooral individuen. Je hebt geen idee welke conclusies een model over jou kan trekken op basis van ogenschijnlijk onschuldige inputs. En die conclusies kunnen gebruikt worden om je te beïnvloeden, te targeten, of te discrimineren - zonder dat je het doorhebt.
Risico 2 - Schaduwgebruik: werknemers gebruiken AI stiekem en bedrijfsdata lekt weg
Dit risico treft vooral bedrijven en wij spreken uit ervaring: dit wordt volledig onderschat. Je kunt een AI-verbod instellen, maar medewerkers gebruiken het tóch. Voor het eerst adopteren consumenten een technologie sneller dan bedrijven. Dat gat tussen werk en privé is groot, en werknemers vullen dat zelf in.
Bij een klant met een AI-verbod bleek 30% van de mensen gewoon ChatGPT te gebruiken. Dat kun je zien via IP-logs bij OpenAI. Dertig procent. Dan heb je dus geen grip meer op wat er gedeeld wordt.
Waarom dit gevaarlijk is
Er verdwijnt gevoelige informatie in systemen waar jij geen controle over hebt. Dat kan gaan om klantdata, code, strategie of concurrentie-informatie.
Samsung in 2023 is het bekende voorbeeld: medewerkers plakten interne code in ChatGPT om even snel te debuggen. Die code is nu onderdeel van de trainingsdata. Je krijgt het er nooit meer uit. En in theorie kan het ooit weer opduiken bij iemand anders.
Risico 3 - Je data wordt gestolen
Net zoals bij ‘vibe coding’ bestaat er ook ‘vibe hacking’. Door generatieve en agentische AI is het een stuk goedkoper en makkelijker geworden om data te stelen.
Generatieve AI maakt het gemakkelijk om op grote schaal echt lijkende kopieën te maken van e-mails, stemmen, foto’s en andere documenten nodig om te hacken.
Agentische AI: AI kan nu zelfstandig acties uitvoeren, waardoor het goedkoper en gemakkelijker wordt om op schaal systemen binnen te dringen en code te schrijven die kwetsbaarheden exploiteert.
De Claude-aanval laat zien wat er mogelijk is
In september 2025 onderschepte Anthropic een grootschalige cyberaanval waarbij hackers - waarschijnlijk gelieerd aan de Chinese staat - hun agentic AI model Claude Code gebruikten om 30 organisaties aan te vallen. Tech-bedrijven, financiële instellingen, overheidsinstanties.
Claude Code werd gebruikt om systemen te analyseren, kwetsbaarheden te vinden, exploit-code schrijven, credentials stelen, data exfiltreren. Op het hoogtepunt maakte de AI duizenden verzoeken, vaak meerdere per seconde - een snelheid die voor menselijke hackers simpelweg onmogelijk is.
Waarom dit gevaarlijk is
Data over jou die bij derde partijen ligt, kan nu nog makkelijker gehackt worden dankzij agentic AI. Het is niet zo lang geleden dat internetcriminelen de privégegevens van 485.000 Nederlandse vrouwen stalen bij laboratorium Clinical Diagnostics. Onderzoeksgegevens, naam- en adresgegevens, namen van zorgverleners, verwijzingen van huisartsen. Data uit meerdere jaren, teruggaand tot 2016.
Daarom is het belangrijk om ook te weten hoe lang je data bewaard wordt. Hoe langer het ergens opgeslagen ligt, hoe groter de kans is dat het in handen komt waar jij geen toestemming voor hebt gegeven.
HELP, wat kan ik hier aan doen?
1. Kies het juiste plan, zet training uit en blijf dit checken
Regels veranderen snel. Begin 2025 zette OpenAI training voor Plus-accounts opeens standaard weer aan. Dus je moet actief zelf ingrijpen. Wij begrijpen natuurlijk dat het oersaai kan zijn, daarom delen wij aanstaande zaterdag in een nieuwe post:
Één overzichtstabel van de platforms ChatGPT, Claude en Gemini waar je in één keer ziet:
Wordt mijn data gebruikt voor training?
Is er een opt-out mogelijkheid? En zo ja, wat zijn de nadelen?
Hoe lang wordt je data bewaard?
Worden je chats gebruikt voor menselijke review?
Voldoet het aan de officiële beveiligings- en privacystandaarden?
De prompt die wij gebruiken om privacy policies van tools uit te pluizen naar normale taal, die je kunt gebruiken voor alle AI-tools die je naast ChatGPT, Claude, Gemini en Copilot gebruikt, zoals Granola, Fireflies, ...
Geen tijd om te prompten? Dan delen wij ook onze eigen AI Privacy Assistent (GPT) die aan de hand van de naam van een tool jou precies vertelt in normale taal wat je moet weten over je data
2. Behandel AI als een publiek forum
Deel niks wat je morgen niet op een nieuwssite zou willen zien. Dat betekent: geen volledige persoonsgegevens, geen ID-nummers, geen medische info, geen wachtwoorden, geen betaalgegevens.
Bedrijven moeten hier een stap verder in gaan. Maak een AI-policy die echt duidelijk is. Wat mag wel? Wat mag niet? Welke tools zijn toegestaan? Wat doe je bij twijfel? Laat juridisch, IT én gebruikers meekijken. Dit moet je niet in een middagje aftikken.
Let op: Uit het rapport The AI Equation: 2024 AI Business Impact Research blijkt dat 71% van de werknemers meer werktevredenheid ervaart door AI. Dat is een stevig signaal. Dus blokkeer AI niet uit gemak, want medewerkers vinden hun werk er vaak juist beter van. Beter is om het gebruik toe te staan binnen duidelijke, veilige kaders.
3. Voor echt gevoelige data: draai je eigen modellen
Als je écht wilt dat niemand meekijkt, is de enige optie: je eigen AI-model draaien op je eigen hardware. Geen cloud, geen externe partijen, volledige controle.
Dat klinkt duur en ingewikkeld, en dat is het ook. Maar voor organisaties met zeer gevoelige data - denk aan gezondheidszorg, financiële dienstverlening, of defensie - moet het voor data-soevereiniteit.
Is dit iets voor jou? Waarschijnlijk niet. Tenzij je werkt met data die wettelijk beschermd is (medisch, juridisch) of waar enorm veel geld mee gemoeid is. Voor de meeste gevallen volstaan zakelijke accounts met goed beleid.
Maar het is goed om te weten dat de optie bestaat. Want het laat zien dat je niet hoeft te kiezen tussen “AI gebruiken” of “privacy bewaken”. Je kunt beide hebben: het is alleen een kwestie van weten welk niveau van controle je écht nodig hebt.
Samengevat in een infographic
Source: her/ai prompt in Nano Banana Pro by Gemini 3
Wij willen Beaubine Adriaansen, Senior Privacy Officer bij de GGD Amsterdam, die momenteel druk bezig is met een postacademische specialisatieopleiding Privacyrecht enorm bedanken voor haar expertcheck en input op dit artikel.